
1. 세그먼트 트리란? - 목적, 내부 구조, 동작 원리
- 목적:
배열의 특정 구간에 대해 계산(예: 합계, 최소값, 최대값)을 빠르게 수행하기 위함이다.
이를 위해 미리 구간별 연산 결과를 저장한다. - 내부 구조:
- 리프 노드: 배열의 각 단일 원소이다.
- 내부 노드: 자식 노드들의 값을 특정 연산(예: 덧셈, 최솟값, 최댓값)으로 결합하여 구간 전체에 대한 결과를 저장한다.
- 동작 원리 :
- 세그먼트 트리 구현의 원리는 분할 정복(Divide and Conquer) 이다.
- 쉽게 말하면 미리 싹 다 계산해서 트리를 만들고 그 트리를 탐색하는 것이다.
- (구간 별 연산 결과를 미리 계산)
- 성능 :
2. 어디에 사용? - 백준 2042
예시) 백준 2042번
1,2,3,4,5 라는 수가 있고, 3번째 수를 6으로 바꾸고 2번째부터 5번째까지 합을 구하라고 한다면 17을 출력하면 된다.
그리고 그 상태에서 다섯 번째 수를 2로 바꾸고 3번째부터 5번째까지 합을 구하라고 한다면 12가 될 것이다.
https://www.acmicpc.net/problem/2042
3. 이해하기
먼저 그림을 보고 이해를 해보자. 다음의 그림은 유튜버 개발자 영맨에서 가져온 그림이다.
(좋은 그림 너무 감사합니다. 문제 생기면 즉시 내리겠습니다.)
탐색

쿼리 합을 구할 때 3 ~ 10까지 하나하나 다 구하는게 아니라, 미리 계산해 놓은 트리를 분할 정복으로 탐색한다.
트리에서 3 ~ 10까지의 합을 구하려면 어떤 요소가 필요한 지 탐색해야 한다.
총 탐색하는 개수가 대략 log n 개이다.(트리 요소 조회는 단순한 배열 접근이므로 O(1)이다.)

업데이트
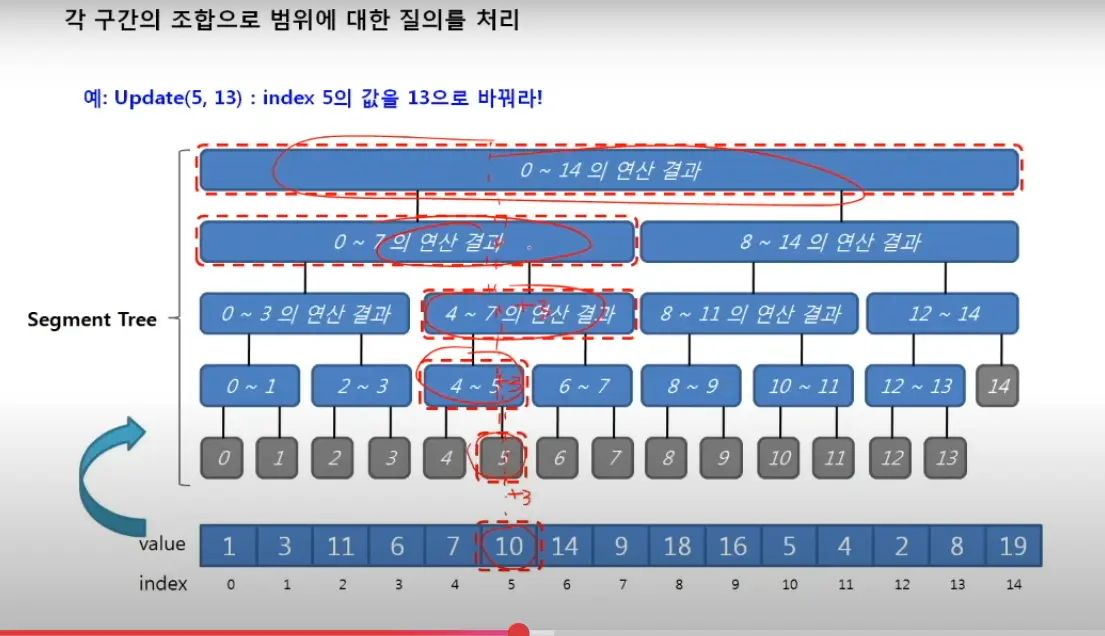
update과정에도 log n이 걸린다. 단순 배열만을 업데이트 하는게 아니라 그 상위 노드도 갱신을 해주어야 할 것이다.
4. 구현 방식
Build 시에는 최악의 경우에 4N개의 배열에 값을 할당해야 하므로, 시간복잡도 O(N)
조회 시에는 log N 개의 요소를 조회 해야 하므로 O(log N)
업데이트 시에는 트리 높이 개수 만큼 업데이트 해줘야하므로 O(log N)
설명 없는 버전
#include <iostream>
#include <vector>
using namespace std;
vector<int> a, t;
int mrg(int a, int b) { return a + b; }
int st(int n, int s, int e) {
if (s == e)
return t[n] = a[s];
int mid = s + (e - s) / 2;
return t[n] = mrg(st(n, s, mid), st(n, mid + 1, e));
}
int qry(int n, int s, int e, int l, int r) { // elrs erls
if (e < l || r < s)
return 0;
if (e <= r && l <= s)
return t[n];
int mid = s + (e - s) / 2;
return mrg(qry(n, s, mid, l, r), qry(n, mid + 1, e, l, r));
}
int upt(int n, int s, int e, int i, int v) { // isei
if (i < s || e < i)
return t[n];
if (s == e)
return t[n] = v;
int mid = s + (e - s) / 2;
return t[n] = mrg(upt(2 * n, s, mid, i, v), upt(2 * n + 1, mid + 1, e, i, v));
}
int main() {
int n, m, k;
cin >> n >> m >> k;
int ROOT = 1;
int START = 0;
int END = n - 1;
a.resize(n);
t.resize(n * 4);
for (int i = 0; i < n; i++) {
cin >> a[i];
}
st(ROOT, START, END);
for (int i = 0; i < m + k; i++) {
int a, b, c;
cin >> a >> b >> c;
if (a == 1) {
upt(ROOT, START, END, b - 1, c);
} else {
cout << qry(ROOT, START, END, b - 1, c - 1) << "\n";
}
}
}
/*
백준 2042번
5 2 2
1
2
3
4
5
1 3 6
2 2 5
1 5 2
2 3 5
17
12
*/설명 있는 버전
#include <iostream>
#include <vector>
using namespace std;
vector<int> a, t;
// 결합 함수: 두 값의 합을 반환 (구간 합을 구하기 위한 연산)
int mrg(int a, int b) { return a + b; }
// --- 세그먼트 트리 구축 (Build) ---
// 노드 n이 배열 a의 구간 [s, e]를 담당하도록 세그먼트 트리를 구축합니다.
int st(int n, int s, int e) {
// [기저 조건] 구간에 단 하나의 원소만 있는 경우 (리프 노드)
if (s == e)
return t[n] = a[s]; // 배열 a의 해당 원소 값을 트리 노드 t[n]에 저장 후 반환
// [분할] 현재 구간 [s, e]를 두 부분으로 나눕니다.
int mid = s + (e - s) / 2; // 구간의 중간 인덱스 계산 (overflow를 방지하는 방식)
// [정복] 재귀 호출을 통해 좌측 구간 [s, mid]와 우측 구간 [mid+1, e]에 대한 결과를 구합니다.
// 두 결과를 결합 함수 mrg로 합산한 값을 현재 노드 t[n]에 저장하고 반환합니다.
return t[n] = mrg(st(n, s, mid), st(n, mid + 1, e));
}
// --- 구간 질의 (Query) ---
// 노드 n이 담당하는 구간 [s, e] 내에서 질의 구간 [l, r]의 합을 계산합니다.
int qry(int n, int s, int e, int l, int r) {
// [비교 1] 현재 구간 [s, e]와 질의 구간 [l, r]가 전혀 겹치지 않는 경우
if (e < l || r < s)
return 0; // 겹치는 부분이 없으므로 항등원 0을 반환
// [비교 2] 현재 구간 [s, e]가 질의 구간 [l, r]에 완전히 포함되는 경우
if (l <= s && e <= r)
return t[n]; // 미리 계산된 결과인 t[n]을 그대로 반환
// [분할] 현재 구간이 질의 구간과 부분적으로만 겹칠 경우,
// 구간을 반으로 나눠 좌측과 우측에서 각각 질의를 수행합니다.
int mid = s + (e - s) / 2;
// [정복] 좌측 구간 [s, mid]와 우측 구간 [mid+1, e]의 질의 결과를 결합 함수 mrg로 합산해 반환합니다.
return mrg(qry(n, s, mid, l, r), qry(n, mid + 1, e, l, r));
}
// --- 업데이트 (Update) ---
// 노드 n이 담당하는 구간 [s, e] 내에서 배열 a의 인덱스 i를 새로운 값 v로 업데이트합니다.
int upt(int n, int s, int e, int i, int v) {
// [기저 조건 1] 업데이트할 인덱스 i가 현재 구간 [s, e]에 포함되지 않는 경우
if (i < s || e < i)
return t[n]; // 아무 변화가 없으므로 현재 노드 t[n]을 그대로 반환
// [기저 조건 2] 현재 구간이 단일 원소인 경우 (리프 노드)
if (s == e)
return t[n] = v; // 해당 원소를 새로운 값 v로 업데이트하고 반환
// [분할] 현재 구간 [s, e]를 반으로 나눕니다.
int mid = s + (e - s) / 2;
// [정복] 좌측 자식(노드 2*n)과 우측 자식(노드 2*n+1)에서 재귀적으로 업데이트를 수행합니다.
// 두 결과를 결합 함수 mrg로 합산해 현재 노드 t[n]의 값을 갱신한 후 반환합니다.
return t[n] = mrg(upt(2 * n, s, mid, i, v), upt(2 * n + 1, mid + 1, e, i, v));
}
int main() {
int n, m, k;
cin >> n >> m >> k;
int ROOT = 1, START = 0, END = n - 1;
// 배열과 세그먼트 트리 저장 공간 할당
a.resize(n);
t.resize(n * 4); // 최악의 경우에도 충분한 크기를 확보하기 위해 4*n 크기 할당
// 배열 입력
for (int i = 0; i < n; i++) {
cin >> a[i];
}
// 세그먼트 트리 구축: 전체 구간 [0, n-1]에 대해 구축
st(ROOT, START, END);
// m + k 번의 연산 수행 (업데이트와 질의)
for (int i = 0; i < m + k; i++) {
int type, b, c;
cin >> type >> b >> c;
if (type == 1) {
// 업데이트 연산: 배열의 b번째 원소를 c로 변경 (인덱스 보정: 0부터 시작)
upt(ROOT, START, END, b - 1, c);
} else {
// 질의 연산: 배열의 b번째부터 c번째 원소까지의 구간 합 출력 (인덱스 보정)
cout << qry(ROOT, START, END, b - 1, c - 1) << "\n";
}
}
}5. 배열의 크기를 4N으로 하는 이유
세그먼트 트리에서 배열 크기를 4N으로 잡는 이유는, 최악의 경우 필요한 노드 수를 안전하게 수용하기 위해서이다.
왜 최악의 경우 필요한 노드의 수가 4N개 일까?
- N이 2의 거듭제곱인 경우
- 배열의 크기 N이 정확히 $2^k$ (즉, 2의 거듭제곱)라면, 세그먼트 트리는 빈 노드가 없는 완전 이진 트리가 되어 노드의 총 개수는 $2N−1$이 된다.
- 예를 들어, $N=8$일 때, 노드 수는 $2×8−1=15$개이다.
- N이 2의 거듭제곱이 아닌 경우
- 실제로 입력 N이 2의 거듭제곱이 아니라면, 세그먼트 트리는 빈 노드가 있는 완전 이진 트리로 구성됩니다. 이때, 리프 노드의 수는 N이 아니라 다음 2의 거듭제곱 값 M (즉, $M = 2^{\lceil \log_2 N \rceil}$)을 기준으로 구성된다.
- 이 경우, 트리의 총 노드 수는 $2M−1$이 된다.
- 최악의 경우 4N이 되는 이유
- M은 N보다 크거나 같지만, $M<2N$을 항상 만족한다.
- 따라서 $2M−1<2(2N)−1=4N−1$이 된다.
- 즉, 최악의 경우라도 필요한 노드 수는 $4N−1$개 미만이다.
'알고리즘' 카테고리의 다른 글
| [C++][백준] 6593번 - 상범 빌딩 + DFS/BFS 기초(+백준 1260번) (0) | 2025.03.13 |
|---|---|
| 백준 1707 이분 그래프 (3) | 2025.01.17 |
| 백준, 카데인 알고리즘 (0) | 2025.01.15 |
| 백준 32350번 오버킬(overkill) 문제풀이 (2) | 2025.01.14 |
| 알고리즘 문풀 : 2023 KAKAO BLIND RECRUITMENT 개인정보 수집 유효기간 (2) | 2025.01.13 |
1. 세그먼트 트리란? - 목적, 내부 구조, 동작 원리
- 목적:
배열의 특정 구간에 대해 계산(예: 합계, 최소값, 최대값)을 빠르게 수행하기 위함이다.
이를 위해 미리 구간별 연산 결과를 저장한다. - 내부 구조:
- 리프 노드: 배열의 각 단일 원소이다.
- 내부 노드: 자식 노드들의 값을 특정 연산(예: 덧셈, 최솟값, 최댓값)으로 결합하여 구간 전체에 대한 결과를 저장한다.
- 동작 원리 :
- 세그먼트 트리 구현의 원리는 분할 정복(Divide and Conquer) 이다.
- 쉽게 말하면 미리 싹 다 계산해서 트리를 만들고 그 트리를 탐색하는 것이다.
- (구간 별 연산 결과를 미리 계산)
- 성능 :
2. 어디에 사용? - 백준 2042
예시) 백준 2042번
1,2,3,4,5 라는 수가 있고, 3번째 수를 6으로 바꾸고 2번째부터 5번째까지 합을 구하라고 한다면 17을 출력하면 된다.
그리고 그 상태에서 다섯 번째 수를 2로 바꾸고 3번째부터 5번째까지 합을 구하라고 한다면 12가 될 것이다.
https://www.acmicpc.net/problem/2042
3. 이해하기
먼저 그림을 보고 이해를 해보자. 다음의 그림은 유튜버 개발자 영맨에서 가져온 그림이다.
(좋은 그림 너무 감사합니다. 문제 생기면 즉시 내리겠습니다.)
탐색
쿼리 합을 구할 때 3 ~ 10까지 하나하나 다 구하는게 아니라, 미리 계산해 놓은 트리를 분할 정복으로 탐색한다.
트리에서 3 ~ 10까지의 합을 구하려면 어떤 요소가 필요한 지 탐색해야 한다.
총 탐색하는 개수가 대략 log n 개이다.(트리 요소 조회는 단순한 배열 접근이므로 O(1)이다.)
업데이트
update과정에도 log n이 걸린다. 단순 배열만을 업데이트 하는게 아니라 그 상위 노드도 갱신을 해주어야 할 것이다.
4. 구현 방식
Build 시에는 최악의 경우에 4N개의 배열에 값을 할당해야 하므로, 시간복잡도 O(N)
조회 시에는 log N 개의 요소를 조회 해야 하므로 O(log N)
업데이트 시에는 트리 높이 개수 만큼 업데이트 해줘야하므로 O(log N)
설명 없는 버전
#include <iostream>
#include <vector>
using namespace std;
vector<int> a, t;
int mrg(int a, int b) { return a + b; }
int st(int n, int s, int e) {
if (s == e)
return t[n] = a[s];
int mid = s + (e - s) / 2;
return t[n] = mrg(st(n, s, mid), st(n, mid + 1, e));
}
int qry(int n, int s, int e, int l, int r) { // elrs erls
if (e < l || r < s)
return 0;
if (e <= r && l <= s)
return t[n];
int mid = s + (e - s) / 2;
return mrg(qry(n, s, mid, l, r), qry(n, mid + 1, e, l, r));
}
int upt(int n, int s, int e, int i, int v) { // isei
if (i < s || e < i)
return t[n];
if (s == e)
return t[n] = v;
int mid = s + (e - s) / 2;
return t[n] = mrg(upt(2 * n, s, mid, i, v), upt(2 * n + 1, mid + 1, e, i, v));
}
int main() {
int n, m, k;
cin >> n >> m >> k;
int ROOT = 1;
int START = 0;
int END = n - 1;
a.resize(n);
t.resize(n * 4);
for (int i = 0; i < n; i++) {
cin >> a[i];
}
st(ROOT, START, END);
for (int i = 0; i < m + k; i++) {
int a, b, c;
cin >> a >> b >> c;
if (a == 1) {
upt(ROOT, START, END, b - 1, c);
} else {
cout << qry(ROOT, START, END, b - 1, c - 1) << "\n";
}
}
}
/*
백준 2042번
5 2 2
1
2
3
4
5
1 3 6
2 2 5
1 5 2
2 3 5
17
12
*/설명 있는 버전
#include <iostream>
#include <vector>
using namespace std;
vector<int> a, t;
// 결합 함수: 두 값의 합을 반환 (구간 합을 구하기 위한 연산)
int mrg(int a, int b) { return a + b; }
// --- 세그먼트 트리 구축 (Build) ---
// 노드 n이 배열 a의 구간 [s, e]를 담당하도록 세그먼트 트리를 구축합니다.
int st(int n, int s, int e) {
// [기저 조건] 구간에 단 하나의 원소만 있는 경우 (리프 노드)
if (s == e)
return t[n] = a[s]; // 배열 a의 해당 원소 값을 트리 노드 t[n]에 저장 후 반환
// [분할] 현재 구간 [s, e]를 두 부분으로 나눕니다.
int mid = s + (e - s) / 2; // 구간의 중간 인덱스 계산 (overflow를 방지하는 방식)
// [정복] 재귀 호출을 통해 좌측 구간 [s, mid]와 우측 구간 [mid+1, e]에 대한 결과를 구합니다.
// 두 결과를 결합 함수 mrg로 합산한 값을 현재 노드 t[n]에 저장하고 반환합니다.
return t[n] = mrg(st(n, s, mid), st(n, mid + 1, e));
}
// --- 구간 질의 (Query) ---
// 노드 n이 담당하는 구간 [s, e] 내에서 질의 구간 [l, r]의 합을 계산합니다.
int qry(int n, int s, int e, int l, int r) {
// [비교 1] 현재 구간 [s, e]와 질의 구간 [l, r]가 전혀 겹치지 않는 경우
if (e < l || r < s)
return 0; // 겹치는 부분이 없으므로 항등원 0을 반환
// [비교 2] 현재 구간 [s, e]가 질의 구간 [l, r]에 완전히 포함되는 경우
if (l <= s && e <= r)
return t[n]; // 미리 계산된 결과인 t[n]을 그대로 반환
// [분할] 현재 구간이 질의 구간과 부분적으로만 겹칠 경우,
// 구간을 반으로 나눠 좌측과 우측에서 각각 질의를 수행합니다.
int mid = s + (e - s) / 2;
// [정복] 좌측 구간 [s, mid]와 우측 구간 [mid+1, e]의 질의 결과를 결합 함수 mrg로 합산해 반환합니다.
return mrg(qry(n, s, mid, l, r), qry(n, mid + 1, e, l, r));
}
// --- 업데이트 (Update) ---
// 노드 n이 담당하는 구간 [s, e] 내에서 배열 a의 인덱스 i를 새로운 값 v로 업데이트합니다.
int upt(int n, int s, int e, int i, int v) {
// [기저 조건 1] 업데이트할 인덱스 i가 현재 구간 [s, e]에 포함되지 않는 경우
if (i < s || e < i)
return t[n]; // 아무 변화가 없으므로 현재 노드 t[n]을 그대로 반환
// [기저 조건 2] 현재 구간이 단일 원소인 경우 (리프 노드)
if (s == e)
return t[n] = v; // 해당 원소를 새로운 값 v로 업데이트하고 반환
// [분할] 현재 구간 [s, e]를 반으로 나눕니다.
int mid = s + (e - s) / 2;
// [정복] 좌측 자식(노드 2*n)과 우측 자식(노드 2*n+1)에서 재귀적으로 업데이트를 수행합니다.
// 두 결과를 결합 함수 mrg로 합산해 현재 노드 t[n]의 값을 갱신한 후 반환합니다.
return t[n] = mrg(upt(2 * n, s, mid, i, v), upt(2 * n + 1, mid + 1, e, i, v));
}
int main() {
int n, m, k;
cin >> n >> m >> k;
int ROOT = 1, START = 0, END = n - 1;
// 배열과 세그먼트 트리 저장 공간 할당
a.resize(n);
t.resize(n * 4); // 최악의 경우에도 충분한 크기를 확보하기 위해 4*n 크기 할당
// 배열 입력
for (int i = 0; i < n; i++) {
cin >> a[i];
}
// 세그먼트 트리 구축: 전체 구간 [0, n-1]에 대해 구축
st(ROOT, START, END);
// m + k 번의 연산 수행 (업데이트와 질의)
for (int i = 0; i < m + k; i++) {
int type, b, c;
cin >> type >> b >> c;
if (type == 1) {
// 업데이트 연산: 배열의 b번째 원소를 c로 변경 (인덱스 보정: 0부터 시작)
upt(ROOT, START, END, b - 1, c);
} else {
// 질의 연산: 배열의 b번째부터 c번째 원소까지의 구간 합 출력 (인덱스 보정)
cout << qry(ROOT, START, END, b - 1, c - 1) << "\n";
}
}
}5. 배열의 크기를 4N으로 하는 이유
세그먼트 트리에서 배열 크기를 4N으로 잡는 이유는, 최악의 경우 필요한 노드 수를 안전하게 수용하기 위해서이다.
왜 최악의 경우 필요한 노드의 수가 4N개 일까?
- N이 2의 거듭제곱인 경우
- 배열의 크기 N이 정확히 $2^k$ (즉, 2의 거듭제곱)라면, 세그먼트 트리는 빈 노드가 없는 완전 이진 트리가 되어 노드의 총 개수는 $2N−1$이 된다.
- 예를 들어, $N=8$일 때, 노드 수는 $2×8−1=15$개이다.
- N이 2의 거듭제곱이 아닌 경우
- 실제로 입력 N이 2의 거듭제곱이 아니라면, 세그먼트 트리는 빈 노드가 있는 완전 이진 트리로 구성됩니다. 이때, 리프 노드의 수는 N이 아니라 다음 2의 거듭제곱 값 M (즉, $M = 2^{\lceil \log_2 N \rceil}$)을 기준으로 구성된다.
- 이 경우, 트리의 총 노드 수는 $2M−1$이 된다.
- 최악의 경우 4N이 되는 이유
- M은 N보다 크거나 같지만, $M<2N$을 항상 만족한다.
- 따라서 $2M−1<2(2N)−1=4N−1$이 된다.
- 즉, 최악의 경우라도 필요한 노드 수는 $4N−1$개 미만이다.
'알고리즘' 카테고리의 다른 글
| [C++][백준] 6593번 - 상범 빌딩 + DFS/BFS 기초(+백준 1260번) (0) | 2025.03.13 |
|---|---|
| 백준 1707 이분 그래프 (3) | 2025.01.17 |
| 백준, 카데인 알고리즘 (0) | 2025.01.15 |
| 백준 32350번 오버킬(overkill) 문제풀이 (2) | 2025.01.14 |
| 알고리즘 문풀 : 2023 KAKAO BLIND RECRUITMENT 개인정보 수집 유효기간 (2) | 2025.01.13 |